Published
- 3 min read
Building a RAG system using Cluster Semantic Chunking
Introduction
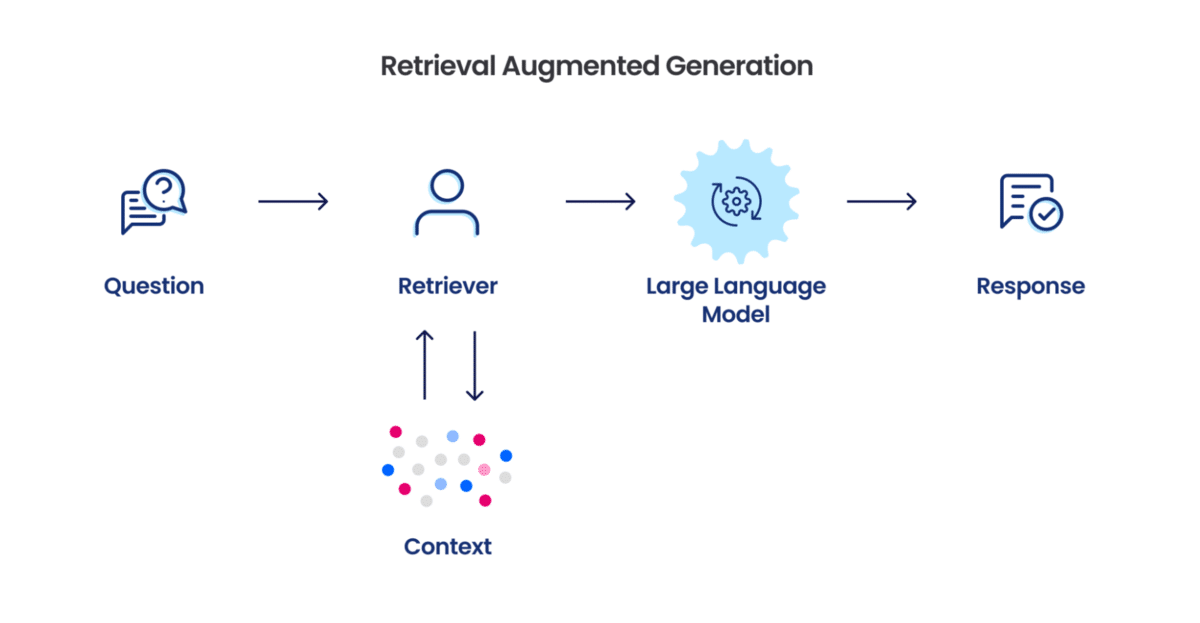
Have you ever asked ChatGPT a question and it answered horribly wrong? One of the ways to solve this problem of LLMs hallucinating is by using Retrieval-Augmented Generation (RAG).
RAG systems allow more precision by only giving the LLMs the context they need to answer the question given.
One of the many steps involving the development of a RAG system is chunking, which refers to the way the text is broken down into tiny pieces that are easier for the model to digest.
In this article I’ll explain the workings of a RAG system which uses the Cluster Semantic Chunking, a new strategy developed by researchers at ChromaDB
According to their research, this new strategy allows more coherent understanding of the text by connecting pieces of text that are related to each other. I won’t go into details here so make sure to read the research linked above if you’re curious.
Notebook
The following notebook implements this technique, note that the class ClusterSemanticChunker takes care of all the work, so to know more make sure to read the class implementation.
Feel free to download the notebook from my github repository here!
## RAG using Cluster Semantic Chunker and PGVector
> The `ClusterSemanticChunker` aims to produce globally optimal chunks by maximizing the sum of cosine similarities within chunks, up to a user-specified maximum length.
> Intuitively, this preserves as much similar semantic information as possible across the document, while compacting relevant information in each chunk.
[*ChromaDB*](https://research.trychroma.com/evaluating-chunking)
This notebook implements a RAG system using a chunking algorithm proposed by ChromaDB researchers called **Cluster Semantic Chunking**, alongside a **PGVector** database and **OpenAI** API.from chunking_evaluation.chunking import ClusterSemanticChunker
import tiktoken
from chromadb.utils import embedding_functions
from chunking_evaluation.utils import openai_token_count
import os
from langchain_postgres import PGVector
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.documents import Document
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from typing import Dict, Any, List
import dotenv
dotenv.load_dotenv()def analyze_chunks(chunks, use_tokens=False):
print("\nNumber of Chunks:", len(chunks))
middle_chunk_index = len(chunks)//2
print("\n", "="*50, "1st Chunk", "="*50,"\n", chunks[0])
print("\n", "="*50, f"Middle Chunk (number:{middle_chunk_index})", "="*50,"\n", chunks[middle_chunk_index])
print("\n", "="*50, "Last Chunk", "="*50,"\n", chunks[-1])
chunk1, chunk2 = chunks[middle_chunk_index - 1], chunks[middle_chunk_index]
if use_tokens:
encoding = tiktoken.get_encoding("cl100k_base")
tokens1 = encoding.encode(chunk1)
tokens2 = encoding.encode(chunk2)
for i in range(len(tokens1), 0, -1):
if tokens1[-i:] == tokens2[:i]:
overlap = encoding.decode(tokens1[-i:])
print("\n", "="*50, f"\nOverlapping text ({i} tokens):", overlap)
return
print("\nNo token overlap found")
else:
for i in range(min(len(chunk1), len(chunk2)), 0, -1):
if chunk1[-i:] == chunk2[:i]:
print("\n", "="*50, f"\nOverlapping text ({i} chars):", chunk1[-i:])
return
print("\nNo character overlap found")with open("./pride_and_prejudice.txt", 'r', encoding='utf-8') as file:
document = file.read()
print("First 1000 Characters: ", document[:1000])embedding_function = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-3-large"
)cluster_chunker = ClusterSemanticChunker(
max_chunk_size=200,
embedding_function=embedding_function,
length_function=openai_token_count
)
cluster_chunker_chunks = cluster_chunker.split_text(document)analyze_chunks(cluster_chunker_chunks)embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
connection = "postgresql+psycopg://langchain:langchain@localhost:6024/langchain"
collection_name = "my_docs"
# Save yourself the pain and don't use FAISS
vector_store = PGVector(
embeddings=embeddings,
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)docs = [Document(page_content=chunk, metadata={"id": i}) for i, chunk in enumerate(cluster_chunker_chunks)]
ids = vector_store.add_documents(docs, ids=[doc.metadata["id"] for doc in docs])query = "Who's the author of this piece of text?"results = vector_store.similarity_search_with_relevance_scores(query, k=3)
for doc, score in results:
print(f"* (SCORE: {score}) {doc.page_content} [{doc.metadata}]")def answer_rag(vector_store: PGVector, query, format=False) -> Dict[str, Any]:
llm = ChatOpenAI(temperature=0.0, model_name="gpt-4o-mini-2024-07-18")
eval_prompt = PromptTemplate.from_template("""
Answer the following question based on the provided context
<Question>
{query}
</Question>
<Context>
{context}
</Context>
""")
eval_chain = eval_prompt | llm | StrOutputParser()
results = vector_store.similarity_search_with_relevance_scores(query, k=3)
context = [doc.page_content for [doc, _] in results]
context_text = "\n".join(context)
eval_result = eval_chain.invoke({
"query": query,
"context": context_text
})
result = f"## Question:\n{query}\n## Answer:\n{eval_result}"
if format:
print(result)
else:
return resultanswer_rag(vector_store, query, True)Demo
You can visit the working demo I’ve developed on my website here
Conclusion
Thank you for reading this article, if you have any questions please feel free to contact me through my socials above!